![]()

- July 10 2024
Multimodal AI – Shaping the Future of Commerce Search and Product Discovery
By Oliver Tan, CEO ViSenze
Welcome back to AI Sense and Cents! We are just back from NRF APAC 2024 where we unveiled our pathbreaking Multi-Search. Suffice it to say that we were thrilled with the reception! But for folks who couldn’t see Multi-Search in action, here’s a deep dive from our CEO, Oliver Tan. In this comprehensive overview, Oliver covers the evolution of Multimodal AI, how it works, the retail challenges it can solve easily and much more. Read on!
Evolution of Commerce Search

Over a decade ago, ViSenze developed visual search AI to complement keyword-based product searches, addressing the significant gap in search capabilities in not being able to process visual content. The landscape of ecommerce search continued to evolve rapidly; from basic keyword search to advanced faceted search and filtering to semantic search technologies like Apache Solr and Elasticsearch.
The standard product search capabilities today usually include keyword, visual, and natural language that support some semantic search via natural language technologies, vector embeddings, and/or graphs to understand query intent and map products to that intent
Gartner Magic Quadrant for Search and Product Discovery, May 2024
Today, search and recommendations drive up to 50% of GMV in many major marketplaces and retailers. Increased advancement in generative AI in the last 2 years, particularly in large language models (LLMs), has significantly improved the understanding of complex search terms and semantic queries, making these search engines even more contextually aware and intuitive for users and shaping the shopping experience further.
Introducing Multimodal AI in Commerce Search
At ViSenze, we see the different ways of search coming together in the next wave that will transform product search and discovery. By combining different modalities of input and output data (whether text, semantic, or image) into an intelligent, seamless process we call Multi-Search, AI models now reason across these inputs for more nuanced understanding and render highly relevant and useful results. This approach mimics real-world shopping experiences, allowing shoppers to switch effortlessly between intent and discovery search terms.
They can also utilize conversational queries with visual cues, such as images or videos, and in different languages. Just like how human communication is multimodal and real-world shopping is a sensory-based human experience, Multi-Search aims to replicate this by enabling users to search in ways that feel most natural to them, whether for looking for an evening dress outfit for a party or a new luxury couch with a matching coffee table that matches the aesthetics of their living room.
Instead of text-to-text or image-to-image search, a shopper starts with text and/or image in a single query or series of queries to find products with rich multimedia content.
A Richer Understanding
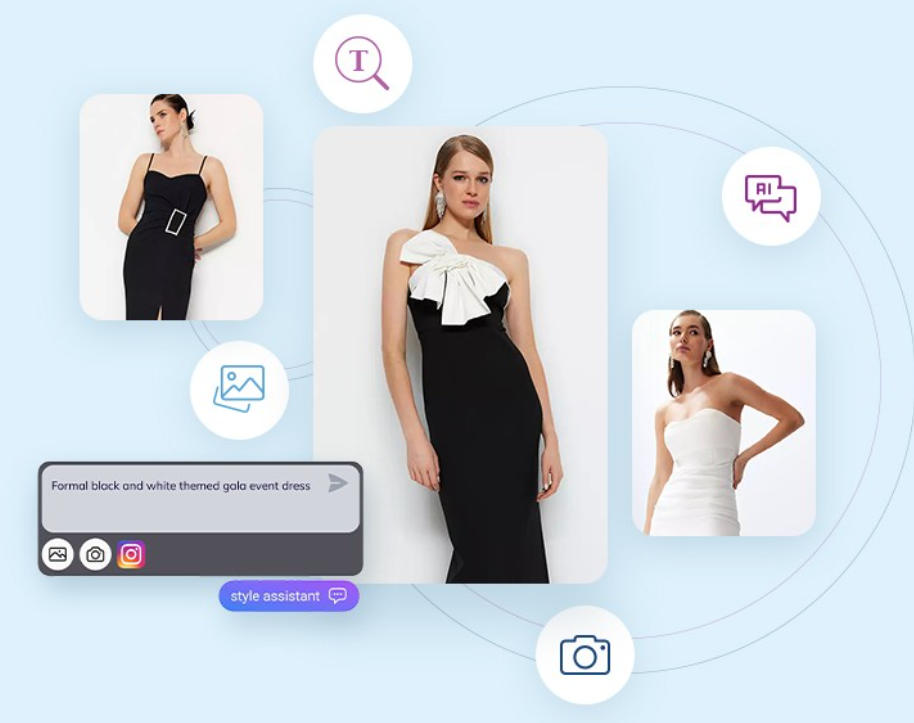
Conventional commerce search engines rely heavily on keyword matching, often leading to irrelevant results and a frustrating experience. Even with natural language support, these product search engines can still struggle with limitations such as ambiguity, context understanding, and complex queries.
Retailers also struggle with extensive rule configurations and tuning to improve the performance of these commerce search engines (which are mostly trained on structured data search and filtering). Even with semantic search engines (which usually require less complex rule-based configurations), the heavy reliance on the quality and consistency of underlying data can still limit the performance of semantic search, as data quality is often less than complete and comprehensive.
In contrast, multimodal search engines leverage both structured and unstructured data, developing a much deeper and contextual understanding of images, sounds, text terms, and context in the search query. For retailers, this reduces the need for query rule processing (such as exact matching, filtering) and extensive rule configurations. Instead, it leverages the combined capabilities of natural language understanding, context comprehension, and auto-learning in multimodal models.
For shoppers, this delivers a more nuanced and accurate interpretation of their queries and better outcomes, such as:
Enhanced User Experience: Users can express their needs more naturally by querying the search engine (such as “show me elegant long dresses with pockets under $100 from sustainable brands”) and/or uploading a picture of an outfit they like and then querying the search further for style recommendations.
Improved Accuracy and Relevance: Multimodal AI interprets the context and nuances of queries more effectively, leading to more specific and relevant results and reducing the time that goes into sifting through unrelated products.
Facilitated Discovery: Users can uncover items they might not have found through text search alone, broadening their discovery options.
Support for Complex Queries: Multimodal search handles complex queries involving style, aesthetics, and personal preferences much better than single-modality searches.
Adaptation to Evolving Shopping Behaviors: A conversational multimodal chatbot or shopping assistant offers a dynamic and interactive shopping experience, meeting the demand for more efficient and engaging ways to discover products.
Current Results, Breakthrough Performances, & Challenges
Various empirical studies consistently show that multimodal models are outperforming unimodal counterparts, providing richer, more accurate, and contextually relevant outputs. For instance, combining textual and visual data has significantly improved the accuracy of product recommendations and search relevance.
Earlier this year, Amazon launched Rufus (beta), an expert shopping assistant that, although currently limited to text-based inputs, is expected to evolve towards integrating multimodal inputs like images and semantics in the future.
ViSenze’s multimodal commerce engine – Multi-Search – combines multiple modalities (text, language, images, video, voice) into a unified vector representation, enabling the AI models to leverage strengths from each modality, which far exceeds unimodal benchmarks (keywords, semantic, image) in early test with pilot clients. These tests were conducted with fashion retailers on multimodal interfaces and experiences – ranging from hybrid search to AI shopping assistant.
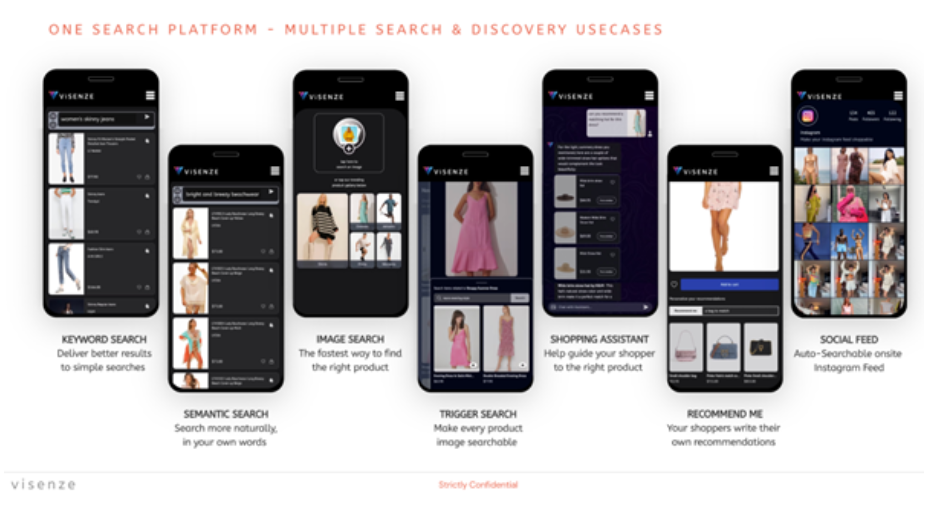
By integrating these modalities into a unified vector architecture, our multimodal search engine was able to:
Contextualize: understand the query context, including entities, relationships, and concepts.
Intent Identification: recognize the searcher’s intent, such as informational or transactional.
Entity Disambiguation: resolve ambiguities in entities, like names or locations.
Relationship Analysis: identify relationships between entities, like product features or user preferences.
Semantic Role Labeling: identify roles like “explore” or “purchase” to understand action and intent.
Enhance Search Accuracy – combining text and image data, where it exists, to provide more precise search results, such as accurately matching color, style, and seasonal context.
Leveraging their own customer data, retailers are further able to:
Improve user engagement: personalized recommendations based on user profiles and behavior patterns to align suggestions with user preferences
Optimize conversion rates: dynamically re-ranking search results based on conversion data increases the relevance of search results, leading to increased sales.
However, there were challenges too. Just like LLMs and ChatGPT, multimodal ecommerce search isn’t perfect and faces its own challenges such as consistent reasoning across input data, context retention, and following instructions, especially in conversational mode. Through continuous feedback loop and reinforcement learning, we believe multimodal-powered search engines will get better.
“Multimodal: AI’s new frontier: AI models that process multiple types of information at once bring even bigger opportunities, along with more complex challenges, than traditional unimodal AI.”
MIT Tech Review, May 2024
How It Works: Model Architecture
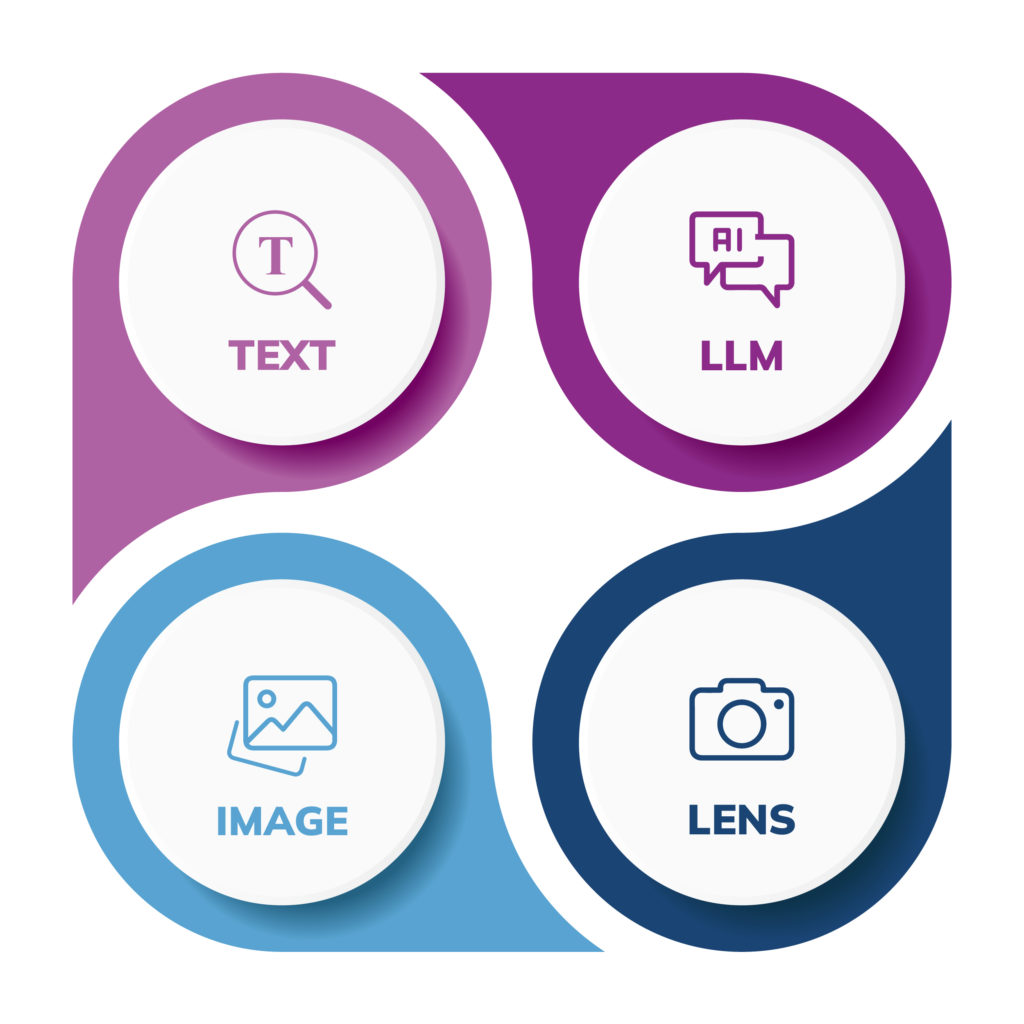
Multimodality integrates various types of data input (keywords, semantics, images/videos, and languages) to create a richer, more intuitive search experience.
Key Components
Vector Architecture: Supports high-volume requests and integrates seamlessly across interaction points like social media, apps, and chatbots.
Hybrid Search: Utilizes both sparse and dense embeddings to enhance search precision.
Transformer Models for Text Encoding: Encodes text queries into high-dimensional vectors, capturing nuanced meanings and relationships.
CNNs for Image Encoding: Processes images through convolutional layers to accurately generate feature vectors representing visual content.
API Integration: Provides a single API-ready solution combining keyword, semantic, and image search queries.
Why It Matters in Commerce Search and Future Directions
The integration of multimodal AI into ecommerce search offers new ways to deliver enhanced shopper experiences, increase efficiency in product tagging and captioning, and drive higher conversion rates. The higher contextual relevance or specificity in product recommendations and search results increases the likelihood of purchases and overall revenue.
Looking ahead, we see the future of commerce search continuing to be shaped by:
Advanced Conversational AI: enhanced interaction through multimodal AI-driven shopping assistants, and in different languages.
Expanded Multimodal Capabilities: integrating additional data types like audio and video for an even richer search experience.
Greater Personalization: incorporating behavioral and user profiles for hyper-personalized recommendations. For instance, the AI automatically recommends more suitable cosmetics for your natural skin color based on your profile.
These advancements will redefine the shopping experience, making it more intuitive, efficient, and enjoyable.
Multimodal AI is not just a technological trend; it’s a paradigm shift. It is AI’s next frontier as we explore and develop AI systems to be more intuitive, empathetic and contextually aware of the environment.
In a $4 trillion ecommerce world that is set to hit at least $6.5 trillion by 2029, we expect to see developments in Multimodal AI reshaping ecommerce search and product discovery with new innovative use cases, elevating shopping experiences to near real-world environments.
This approach will set new heights in enhancing the accuracy and relevance of search results and transform the overall shopping experience. Embracing multimodal AI will be crucial for businesses to stay competitive and meet the ever-evolving needs of consumers.
CONNECT WITH US